
ある会社の新卒採用の応募に1,000人の応募者が集まりました。
この1,000人を「男性と女性に分類すること」や「TOEIC 600点以上のスコア保持者かどうかを分類すること」は、容易な作業と言えます。
それは、分類するための基準が明確であるためです。
一方で、この1,000人を「当社で活躍が期待できる人材かを予測すること」や「当社を退職する可能性が低い人材かを予測すること」は、難しい問題と言えます。
それは、予測(分類)するための、明確な基準がないためです。
このように、明確な基準がない場合に使われる分類の手段として、統計学に基づいた「クラスタリング」あるいは「クラスター分析」と呼ばれる手法あります。
今回の記事では、
- ある製品のSNSや掲示板にある口コミデータを分析してみたい
- 顧客の属性や購買履歴データに基づく分析に興味がある
- 機械学習で使われるクラスタリングの概要を知りたい
という人に向けて、クラスタリング(クラスター分析)を紹介していきます。
データ分析で使われるクラスタリングとは?

クラスタリングとは?
統計学におけるクラスタリング(クラスター分析)とは、あらかじめ分類を行うための基準がないデータに対して、似た属性を持つデータを分類させることを指します。
機械学習における教師なし学習のひとつです。
クラスタリングの活用例として、
- 顧客の購買実績に基づいた商品のレコメンド
- 顧客特性に合わせたダイレクトメール(DM)配布
- 画像処理を用いた製造ラインにおける不良品検出
- 迷惑メールの分類や不正アクセスの検知
などが挙げられます。
ここからは、クラスタリングの2つの手法について紹介していきます。
① 階層的クラスタリング
階層的クラスタリングとは、データ間の類似度が大きいものからまとめていく、あるいは、類似度が小さいものから離していくことで分類を行うクラスタリング手法です。
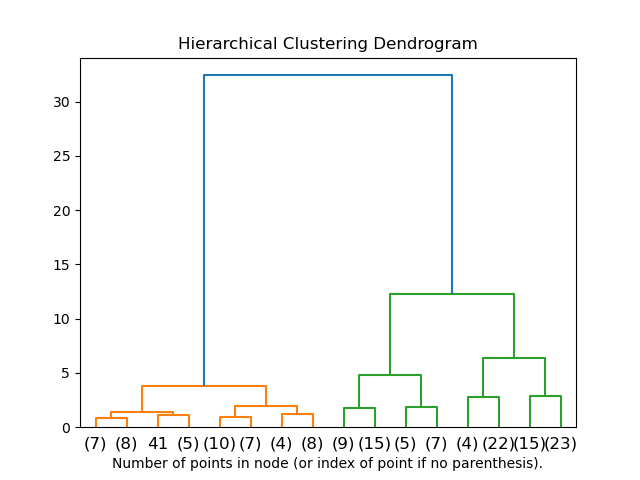
階層的クラスタリングで求められる結果は、デンドログラム(dendrogram)と呼ばれる、トーナメント表のような形で可視化すことができます。
デンドログラムで表現することで、各データの類似性の程度を直感的に確認することができます。場合によっては、当初想定していなかったような結果が導かれることもあります。
代表的な階層的クラスタリング手法として「Ward法(ウォード法)」があります。
この階層的クラスタリングは、サンプルサイズが大きい場合には向いていないため、サンプルサイズが大きい場合には「非階層的クラスタリング」が用いられます。
② 非階層的クラスタリング
非階層的クラスタリングとは、サンプルをあらかじめ決めた数だけに分割するクラスタリング手法です。
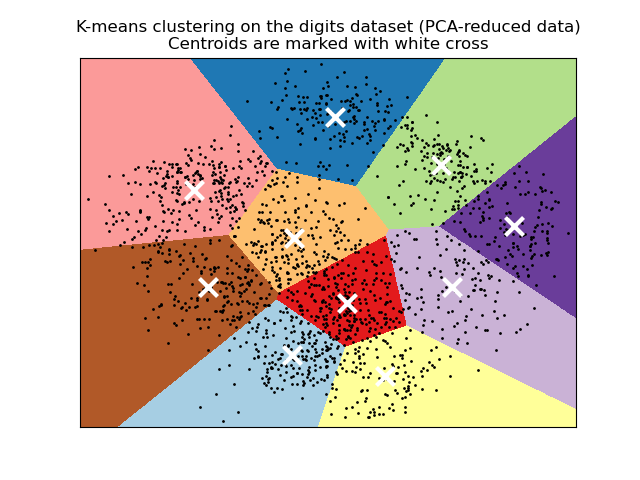
この図は、0から9までの手書きの数字データを非階層的クラスタリングの手法のひとつであるK-means法でクラスタリング化し、低次元空間にデータを投影させ可視化させたものです。
この例を見て分かる通り、0から9までの手書きの数字を分類させるため、クラスタ数は10となっています。
また、クラスタリングの結果は2次元のグラフで表現される場合が多いですが、分析するデータの変数は必ずしも2次元で表現できる必要はなく、多次元の変数をもつデータも分析することができます。
代表的な非階層的クラスタリング手法として「K-means法(K平均法)」があります。
K-means法について
K-means法(K平均法)は、非階層的クラスタリングで用いられる代表的な手法のひとつです。
機械学習の教科書などで登場する0から9の手書き文字を教師なし学習で分類させる問題も、このK-means法で求めることができます。
K-means法のクラスタリングの手順は以下の通りです。
- クラスタ数を決める
- 全データに対してランダムにクラスタ番号を振る
- 2で振り分けたクラスタ毎にデータの重心点(初期値)を求める
- 3(または6)で用意した重心点と、全データの距離を求める
- 各データを、最も距離の小さい重心点に対応したクラスタに振り替える
- クラスタ番号を振り替えたデータセットに対して、ふたたび重心点を求める。
- 大きな変化がなくなるまで、4~6を繰り返す
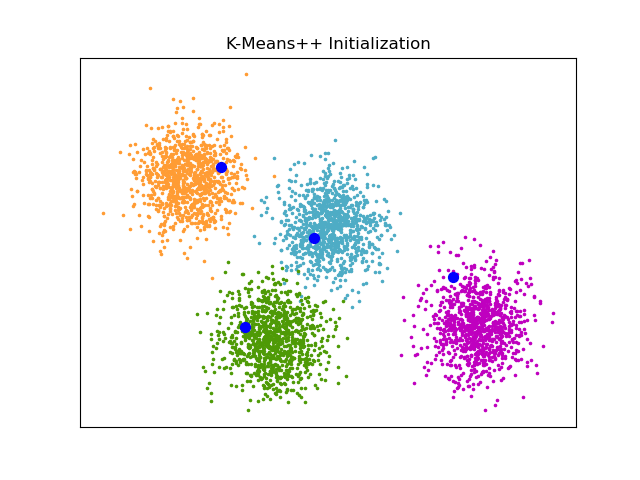
この図は、K-means法を用いてクラスタリングを行った結果を可視化したものです。
4つのクラスタに分類されていることが分かります。また、図中の大きな青い点は、手順3の重心点の初期値を表しています。
さて、K-means法はその手順から見てわかる通り、全ての組み合わせを検証して結果を求めるアルゴリスムではありません。
局所的な最適解を求めるアルゴリズム(ヒューリスティックアルゴリズム)となります。
そのため、K-means法で求められるクラスタリング結果はいつでも最適解とはならないことに注意が必要となります。
なお、K-means法の初期値に依存してしまう問題に対応したK-means++や、クラスタ数を自動的に設定してくれるX-means法という手法もあります。
Pythonで使えるクラスタリング用ライブラリ
最後に、Pythonでクラスタリングを行う場合に使えるライブラリを紹介します。
- scikit-learn … Pythonの代表的な機械学習ライブラリ。クラスタリングを含め、様々な機械学習アルゴリズムをサポートしている。
- tslearn … scikit-learnをベースに開発。時系列データのクラスタリングも可能。
- SciPy … 科学技術計算用のライブラリ。階層化クラスタリングの可視化が可能。
なお、本ページで紹介している図は「scikit-learn.org」より引用しました。
他のアルゴリズムやPythonでの実装例も紹介しているので、興味のある方は参考にしてください。
まとめ
本記事では、機械学習の領域で教師なし学習として用いられるクラスタリングについて紹介していきました。
そして、クラスタリングには、
- K-means法に代表される非階層的クラスタリングと
- Ward法に代表される階層的クラスタリング
の2つのアプローチがあることを紹介しました。
データ分析にクラスタリング手法を用いることで、ある商品に対するSNSや掲示板上の口コミ情報や、顧客の購買履歴の情報に対して、ある特徴をもったグループに分類することができます。
しかし最後に、クラスタリングは、データの分類は行ってくれますが、そのクラスタリング結果が持つ意味までは教えてくれません。
そのため、分類した結果をそのまま他の人に見せても「それで、何?」と言われるだけです。
つまりは、データの分析(クラスタリング)は機械が行ってくれますが、分析結果に意味を持たせることはしてくれませんので、そこは人間(データサイエンティスト)の出番と言えるのかもしれません。
じゃあ。















