
今回の記事では、
- Pythonでできることの応用例を聞いてみたい
- Pythonのウェブスクレイピングや自然言語処理の実例を聞いてみたい
という人に向けて、Pythonに自分好みの日本酒を見つけてもらうための7つのステップを紹介していきます。
Pythonに自分好みの日本酒を見つけてもらうための7つのステップ

「Pythonに自分好み日本酒を見つけてもらう」を、少しだけかみ砕いて表現してみると、「Pythonで日本酒の口コミデータのウェブスクレイピングや自然言語処理を行い、自分が好きな日本酒の銘柄と似た特徴を持つ日本酒の銘柄を見つけ出す」ことになります。
大きく次の7つのステップで構成されます。
- 日本酒の銘柄リストの作成
- 日本酒の口コミデータ収集
- 口コミデータの分かち書き
- 日本酒の辞書作成
- 口コミデータの分析前処理①
- 口コミデータの分析前処理②
- 口コミデータのクラスター分析
7つもステップ(工程)があるなんて、大変そうにも見えますが、果たしてどういったものになるのでしょうか?
次から、各ステップの大まかな流れを紹介していきます。
7つのステップ
① 日本酒の銘柄リストの作成
初めに行うことは、日本酒の銘柄リストの作成です。
WEB上にある情報を用いて銘柄リストを作成するためWEBスクレイピングを使います。
スクレイピングでは、実際のHTMLのコードを確認しながら、抽出したい情報がどのようにHTML上で定義されているかを確認していきます。
そのため、HTMLの知識があった方がスムーズに作業が出来ますが、HTMLの知識がなくても、調べながら&手を動かしながら、実装することもできます。
今回は、「銘柄」「蔵元」「県」「市」の情報を抽出しCSV化したものを銘柄リストとしました。

なお、今回の分析では、蔵元&銘柄情報と口コミデータが充実している「日本酒物語」を活用しました。同サイトは、都道府県別のランキングなどもあるので、日本酒好きの方であれば、ぜひ覗いてもらいたいサイトとなります。
なお、スクレイピングの詳細については別記事「ウェブスクレイピングのメリットと注意点」で紹介しています。
② 日本酒の口コミデータ収集
次に行うことは、銘柄ごとの口コミデータの収集です。
これも、銘柄データと同じように、口コミサイトよりスクレイピングでデータの収集を行います。
別記事「ウェブスクレイピングのメリットと注意点」でも書いた通り、スクレイピングを行う際は、スクレイピング先のサーバーにアクセス負荷をかけないように注意を払う必要があります。
本分析当時の時点で、同サイトには3,910の銘柄が掲載されていました。
そのため、仮に1ページあたり1秒でスクレイピングを行ったとしても、すべての銘柄のデータをスクレイピングするためには3,910秒=1時間以上かかる計算となります。
さらに、ひとつのページに表示される口コミ数は最大10であり、そして、10以上の口コミが掲載されている銘柄は多くあるため、実際の口コミのスクレイプングは、その倍以上の時間がかかることになります。
このようにスクレイピングでは大きな実行待ち時間が必要となる場合があります。
そのため、実行後の大きな手戻り(時間の喪失)が発生しないよう、事前のデバッグ(意図したプログラムにすること)が重要となってきます。
③ 口コミデータの分かち書き
②のスクレイピングで口コミデータが集まった後は、自然言語処理の工程に移ります。
まずは、口コミの文章を品詞レベルに分解します。
口コミの文章を品詞レベルに分解するためには、形態素解析と呼ばれる手法を用いて、文章を分解していきます。
形態素解析では、MeCab(メカブ)と呼ばれるツールを用いました。
そして、形態素解析された結果は分かち書きと呼ばれる形式で出力します。

なお、形態素解析については別記事「SNSや口コミデータの分析で使える形態素解析について」で紹介しています。
④ 日本酒の辞書作成
③の分かち書きの過程で、日本酒の銘柄名も分かち書きされてしまう問題が発生します。
たとえば、「醸し人九平次」という銘柄が「醸し」「人」「九平次」に分解されてしまいます。
この問題に対しては、ユーザー辞書を作成&登録し対処します。
ユーザー辞書作成では、①で用意した銘柄リストを活用します。
ユーザー辞書作成についても別記事「SNSや口コミデータの分析で使える形態素解析について」で紹介しています。
⑤ 口コミデータの分析前処理1
③&④で用意した分かち書きデータを分析する前に、2つの前処理が必要となります。
ひとつは、クラスター分析で役に立たないワードを除外することです。
品詞レベルで分かち書きされたデータの中には、「が」「は」「に」「の」「と」などのような助詞が含まれていたり、「。」「%」「!」などのような句読点や記号などが含まれています。
これらデータは分析では役に立ちません。そのため、正規表現を用いて、分析対象外のワードとして指定&除外します。
そして、基本的な分析対象外ワードの指定を行った後は、残ったワードの登場回数ランキングを確認していきます。
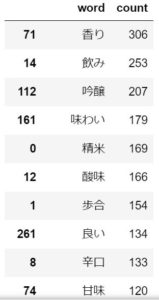
上記の登場回数ランキングの結果を踏まえると、「香り」「味わい」「酸味」「辛口」などは分析で使えそうなワードとします。
一方で、「飲み」「飲ん」などのワードはお酒の特徴を表していないため、分析対象外のワードに指定&除外します。
他にも、「価格」「思う」「アルコール」などのワードは使えないと判断し除外しました。最後に、登場回数が一定回数以下のワードも除外します。
このように、最終的な分析に用いるワードの設定は、人の関与が必要となります。この工程は、プログラミングスキルや統計学の知識を直接的に活かすような工程ではありませんが、除外するワードの選び方次第で、分析結果が変わってくるので、本分析において重要な工程と言えます。
正規表現については別記事「データエンジニア必須スキルの正規表現のすすめ」で紹介しています。
⑥ 口コミデータの分析前処理2
⑤の工程を経て、分析にかけるワードの選択が終わりました。
次に行う前処理は、特徴ベクトルの作成です。特長ベクトルとは、各ワードの出現頻度をベクトルで表したものです。
今回の分析では前処理で残った119のワードに対して、特徴ベクトルを作成しました。


特長ベクトルの作成には「Gensim(ジェンシム)」のライブラリを用います。
⑦ 口コミデータのクラスター分析
⑤と⑥の前処理の工程を経て、ようやく、分析にかけるデータの準備が出来ました。
データの分析にはK-means法(K平均法)を使います。K-means法は教師なし学習でクラスター分析を行うことができるアルゴリズムです。
K-means法については別記事「データ分析で使われるクラスタリングとは?」で紹介しています。
「赤武」に最も味わいの特徴が近い日本酒は?
さて、分析の7つのステップを紹介していきましたが、今回の分析の目的は、私の好きな日本酒のひとつ「赤武」と似た特徴を持つ日本酒の銘柄を探すことでした。
そして、口コミデータをクラスター分析した結果、「赤武(岩手県)」と最も特徴が近いと判断された日本酒の銘柄は、3,910銘柄中、「鷲の尾(岩手県)」「岩木正宗(青森県)」という結果となりました。
偶然にも赤武酒造がある岩手県と同県にある酒蔵の銘柄と、そのお隣の青森県の酒蔵の銘柄が、最も似た特徴を持つ銘柄という結果となりました。
分析の結果では、他にも、「菊の司(岩手県)」や「あさ開き(岩手県)」などの銘柄も、近い位置に分類されていました。
今回のクラスター分析において、前処理を行った後の口コミデータに、県などのエリア情報は含まれておりませんでした。つまり、ただただ「赤武」に近い味わいの銘柄を探してみよう、という考えで始めた分析が、思わぬ形で、「日本酒の味わいは、地域別に、近い特徴が現れる」という一般論を、統計学的にも示唆する結果を得る形で終わりました。
まとめ
今回の記事では、「Pythonに自分好みの日本酒を見つけてもらうための7つのステップ」を紹介していきました。
「銘柄&口コミデータのスクレイピング」「口コミデータの分かち書き」「正規表現などの前処理」「K-means法を用いたクラスター分析」などの7つの工程を経ることで、自分好みの日本酒を求めることが出来ました。
今回紹介した分析の流れは、自分好みの日本酒を見つけるためだけではなく、他のテーマにも応用できる流れであると言えます。
一方で、分析の工程で用いた、それぞれのスキルは、ひとつひとつが奥が深いスキルとなっております。各工程で用いたスキルは、別記事で紹介しておりますので、ぜひ過去の記事も参考にしてみてください。
さて、今回のクラスター分析で、私が好きな日本酒と近い特徴の銘柄を知ることができたのですが、まだどちらの銘柄も味わえていないので、この分析結果が妥当だったのかどうかは、答えが出ていません。。。
じゃあ
関連記事














