
別記事「これさえあれば誰でも将来予想が出来るようになる?時系列予測ライブラリPropfet」で、Facebook社が提供する「Prophet」という時系列予測のライブラリを使うことで、だれでも簡単に時系列予測ができることを紹介しました。
一方、別記事「重回帰分析で将来のビール出荷量を予測してみた」では、回帰分析手法のひとつ、OLS(最小二乗法)を用いたアプローチでスーパードライの出荷数量を予想していきました。
さて、どっちの予測結果の方が優れていたのでしょうか?
今回の記事では
・専用ライブラリと一般的な回帰分析手法のどちらが良い予測精度になるかに興味がある
という人に向けて、時系列予測ライブラリProphetと、回帰分析手法のひとつOLS(最小二乗法)を用いスーパードライの出荷量を予想してみた結果を、比較してみたのでその内容を紹介していきます。
時系列予測ライブラリProphetにオーソドックスな統計学は勝てるのか?

分析の条件は合わせて実施
Prophetと重回帰分析の2つの手法で出荷量を予想していくための条件は、合わせたうえで分析を行いました。
- 予測するのはスーパードライの出荷量
- 学習に用いるデータは、過去の出荷量データ(2012年7月~2017年8月)のみ
- 予想比較するのは、2018年8月~2019年7月の1年間の出荷量
- Prophetはデフォルトの設定
- 重回帰分析はOLS(最小二乗法)を選択
どちらの予想結果がより優れているか?
それぞれの分析手法の流れは別記事で紹介しているので、その辺の説明は割愛し、本記事ではさっそく、比較した結果を見ていきます。
次のグラフは、それぞれの分析手法の予想値と実際の出荷量をプロットしたものです。
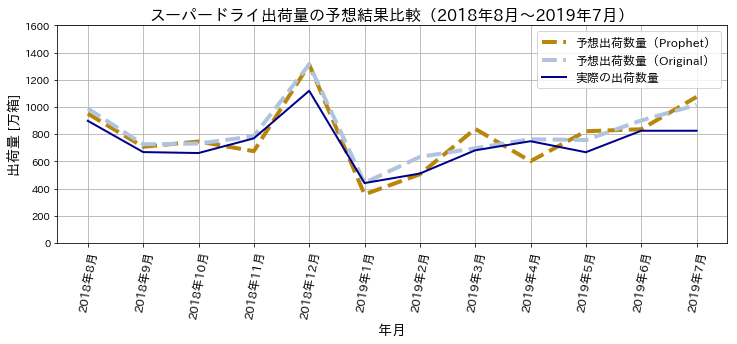
さて、比較した結果はどうでしょうか?
凡例にProphetと書かれた茶色の折れ線がProphetで予想された出荷数量であるのに対して、Originalと書かれた水色の折れ線がオリジナルの最小二乗法で予想された出荷数量となります。
ほとんど差がないように見えますが、いくつかの月で最小二乗法で求めた予想結果の方が、実際の出荷数量に近いことから、オリジナルの手法で求めた予想結果のほうが良いようにも見えます。
今回、定量的に判断するために、平均平方二乗誤差(RMSE)を求めて2つの誤差を比較してみます。
| 分析手法 | RMSE |
|---|---|
| Prophet | 128.29 |
| オリジナル(最小二乗法) | 99.95 |
やはり、僅かではありますが、オリジナルの最小二乗法で求めた予想出荷数量のほうが予想精度が良い結果となりました。
人手で回帰分析を行った方が良い結果となったことを踏まえてどう考えるか?
さて、上記の通り、ライブラリで求められた予測値より、人手で回帰分析を行い求めた結果の方が良い精度となりました。
この結果を踏まえて、自動で予想できるライブラリと人手でチューニングが必要となる回帰分析のどちらの手法が良いと言えるのでしょうか?
今回、回帰分析の結果が良かったのは、たまたまかもしれません。
もっと複雑な周期性のある時系列予想となった場合はProphetの方が良い結果を求めるかもしれません。
Prophetの設定をデフォルトの状態から少し変えれば、より良い精度になったのかもしれません。
分析やコーディングの作業時間を考えると、数行のコーディングとボタン一発でここまでの精度を出せるライブラリを使うほうが効率的と言えます。
そのため、効率重視であれば、Prophetの方が良いのかもしれません。
しかし、今回、回帰分析の中でも最も基本的な手法である、OLS(最小二乗回帰)を用いることで、名が知れたライブラリと同程度の予想が出来た事実に触れて、思うことがあります。
それは別記事「データサイエンティストがデータエンジニアリング力だけでは価値が高まらない理由」でも書いた通り、ツールやライブラリを使いこなすデータエンジニアリングのスキルは重要ではありますが、統計学などのデータサイエンスのスキルもやはり欠かせないスキルであるということです。
Pythonの良いところは、アルゴリズムや数学やプログラミングの深い理解がなくても、いい感じにやりたいことが出来ることです。これは豊富なライブラリの存在のおかげです。
しかし、ライブラリをブラックボックスとして扱うだけでは、他の人と同じような分析結果にしかならない可能性がありますし、そうなると、分析者はツールを使って分析を行うだけの作業者のような存在となってしまいかねません。
我々が単なる作業者となるのではなく、データサイエンティストとして価値を高めていくためには、やはりプログラミングスキルを中心としたデータエンジニア力と同時に統計学などの知識に基づいたデータサイエンス力を磨いていく必要があるのだと思います。
まとめ
ということで、回帰分析から重回帰分析、多重共線性への対処、ライブラリとの比較など、合計6記事に渡ってビールの出荷予測というテーマで、著者自身が手探りで調べながら分析していった結果を紹介してまいりました。
他にも「Pythonに自分好みの日本酒を選んでもらう」や「統計学的に令和婚はあったのか?」などPythonや統計学に関する記事を掲載していますので、チェックしてみてください。
じゃあ















